“The end of small models… or are they?”
Imagine you could replace a team of specialized agents with a single model. That’s the promise of GPT-5.
Introduction
GPT-5 arrived with a bold promise: a single model that unifies the strengths of all previous generations — multimodality, reasoning, strict instruction-following, and function calling.
But for Applied Engineers, the key question is:
Does GPT-5 mark the end of specialized multi-model agentic workflows, or is it just another step in their evolution?
To find out, I put GPT-5 to the test in AI-Agent-Casebook – my open-source project designed to evaluate frameworks, patterns, and models on realistic, complex agentic use cases. Among them: video_script, a fully-fledged agentic workflow combining a Hierarchical Team, Planner/Evaluator, and Corrective RAG.
Could GPT-5 live up to its promise in this demanding context? Here’s what I discovered.
1. GPT-5: A Promise of Convergence
The GPT lineage has been defined by successive leaps in capability:
- GPT-3 (2020): democratization. The first widely accessible LLM API, the reference for few-shot learning.
- GPT-3.5 (2022): natural conversations, thanks to RLHF and ChatGPT.
- GPT-4 (2023): reliability and precision. Function calling and structured JSON outputs marked a turning point for developers.
- GPT-4o (2024): native multimodality with <1s latency → real-time assistants.
- GPT-o1 (2024): reasoning models, capable of tackling long, complex problems with explicit “thinking tokens.”
Now, GPT-5 (2025) arrives as the convergence model: multimodal, strong at reasoning, stylistically refined, strict in instruction-following, with robust tool calling built-in.
Instead of juggling between fast models and deep reasoners, GPT-5 includes an internal routing layer that decides whether to “think harder,” “answer quickly,” or “call a function” depending on the task.
For ChatGPT users, this feels seamless. But for Applied Engineers, the stakes are higher:
If GPT-5 can really do it all, do we still need orchestrated multi-model architectures?
2. AI-Agent-Casebook: The Perfect Evaluation Ground
That’s precisely the purpose of AI-Agent-Casebook:
- Test advanced agentic patterns (Hierarchical Teams, Planner-Evaluator, Corrective RAG, Deep Agents, ReAct).
- Compare frameworks (LangChain, LangGraph, Agents SDK).
- Benchmark multiple models (GPT-4o, Mistral, Claude, etc.).
- On real, complex use cases: generating a video script, onboarding a customer, conducting deep research.
Think of it as a black box evaluation harness: whenever a new model is released, it can be plugged in and measured beyond artificial benchmarks, in the messy reality of agentic systems.
For GPT-5, this was especially relevant:
- Could it replace specialized multi-model workflows?
- Would it simplify architectures, or complicate them?
- What’s the real integration cost?
3. Technical Integration: A Significant Effort
Before tackling video_script, I started with an impact study on agentic-research (YT) and a suite of unit tests to integrate GPT-5 into AI-Agent-Casebook.
Agentic-research: Initial Impact Study
This use case pits two approaches against each other:
- Chain of Thought (CoT) → a “big thinker model” directly orchestrating sub-tasks.
- Deep Agents → a planner delegating execution to specialized smaller models.
With GPT-4o and Mistral, Deep Agents consistently outperformed CoT (more control, more robustness).
With GPT-5, I wanted to see if its internal routing could shift the balance.
The result? The application would run, but not work. Instead of producing a consolidated research report, GPT-5 generated… a training course outline. Why? Because it interpreted prompts more strictly, leaned toward structured pedagogical output, and punished ambiguous instructions.
Lesson: GPT-5 requires model-specific prompts. Retro-compatibility is gone.
Unit Tests: The Pytest Crash
AI-Agent-Casebook includes 20+ unit tests covering core patterns (ReAct, RAG, CoT, etc.).
Here’s what happened when I ran them with GPT-5-mini:
=========================== short test summary info ============================
FAILED tests/customer_onboarding/test_customer_onboarding_assistant_lcel.py::test_customer_onboarding_assistant_eligibility
FAILED tests/customer_onboarding/test_customer_onboarding_assistant_lcel.py::test_customer_onboarding_assistant_faq
FAILED tests/customer_onboarding/test_customer_onboarding_assistant_lcel.py::test_customer_onboarding_assistant_problem
FAILED tests/customer_onboarding/test_faq_agent.py::test_faq_agent
FAILED tests/customer_onboarding/test_problem_agent.py::test_problem_solver_agent
======= 5 failed, 16 passed, 1 skipped, 10 warnings in 788.16s (0:13:08) =======By comparison:
- GPT-4o-mini → 21/21 passed, ~11 minutes.
- Mistral-medium → 21/21 passed, ~8 minutes.
- Claude 4 Sonnet → 21/21 passed, ~13 minutes.
- GPT-5-mini → 16/21 passed, ~13 minutes.
GPT-5 was the only model to fail a subset of tests.
The root causes:
- Unsupported stop codes (LangChain sends them by default).
- Over-strict prompt interpretation, leading to invalid function calls.
Bottom line: GPT-5 demands more integration work than competitors. Where Mistral, GPT-4o, or Claude “just work,” GPT-5 forces prompt revisions, code adjustments, and deeper testing.
Takeaway
The takeaway from integration is clear: bringing a major new model into a real agentic stack is never trivial. Early adoption means hitting rough edges, but that’s the price of testing first. And the more layers you add (LangChain, LangGraph, Agents SDK, litellm…), the more likely you’ll face bugs outside your direct control. That’s why open source matters — it gives you the tools to patch, trace, and understand what’s really happening.
4. Video_script: A Full Agentic Stress Test
The Workflow
Unlike a simple “generate text” task, video_script is a production-grade agentic pipeline, combining several patterns:
- Hierarchical Team via LangGraph: supervisor → researcher → writer → reviewer.
- Planner + Evaluator via Agents SDK: to design and validate the video outline.
- Corrective RAG: retrieval from ChromaDB, enriched with Tavily web search.
- Multiple handoffs and chained tool calls.
In other words: a mini-agentic system in production.
Expectations with GPT-5
- Greater narrative coherence in scripts.
- Less reliance on model orchestration (one strong model instead of many specialized ones).
- More engaging, audience-ready style.
Narrative Results
GPT-5-mini (excerpt) – on the “memory problem” in AI agents:
“Developers should tune retrieval parameters carefully — for example,
chunk_sizeandtop_kdirectly impact recall\@k metrics. Settingtop_ktoo low reduces recall and weakens the memory layer of the agent…”
Dense, technical, and detailed — great for documentation, but unsuitable for a YouTube script aimed at a general technical audience.
Mistral-small (excerpt):
“Imagine trying to talk to someone who forgets everything after each sentence. That’s how most AI agents work today. To fix this, we use three types of memory: short-term, long-term, and external stores like vector databases…”
Clear, simple, and pedagogical — perfect for video content.
GPT-4o-mini (excerpt):
“Welcome back! In this chapter, we’ll cover the different types of memory in AI agents: short-term, long-term, and external. Each plays a role, and combining them is the key to building reliable systems.”
Acceptable, but repetitive (“Welcome back!” every chapter). Less fluid than Mistral.
5. Performance Analysis & Ranking
Beyond style and content, hard metrics tell the story.
Raw Results
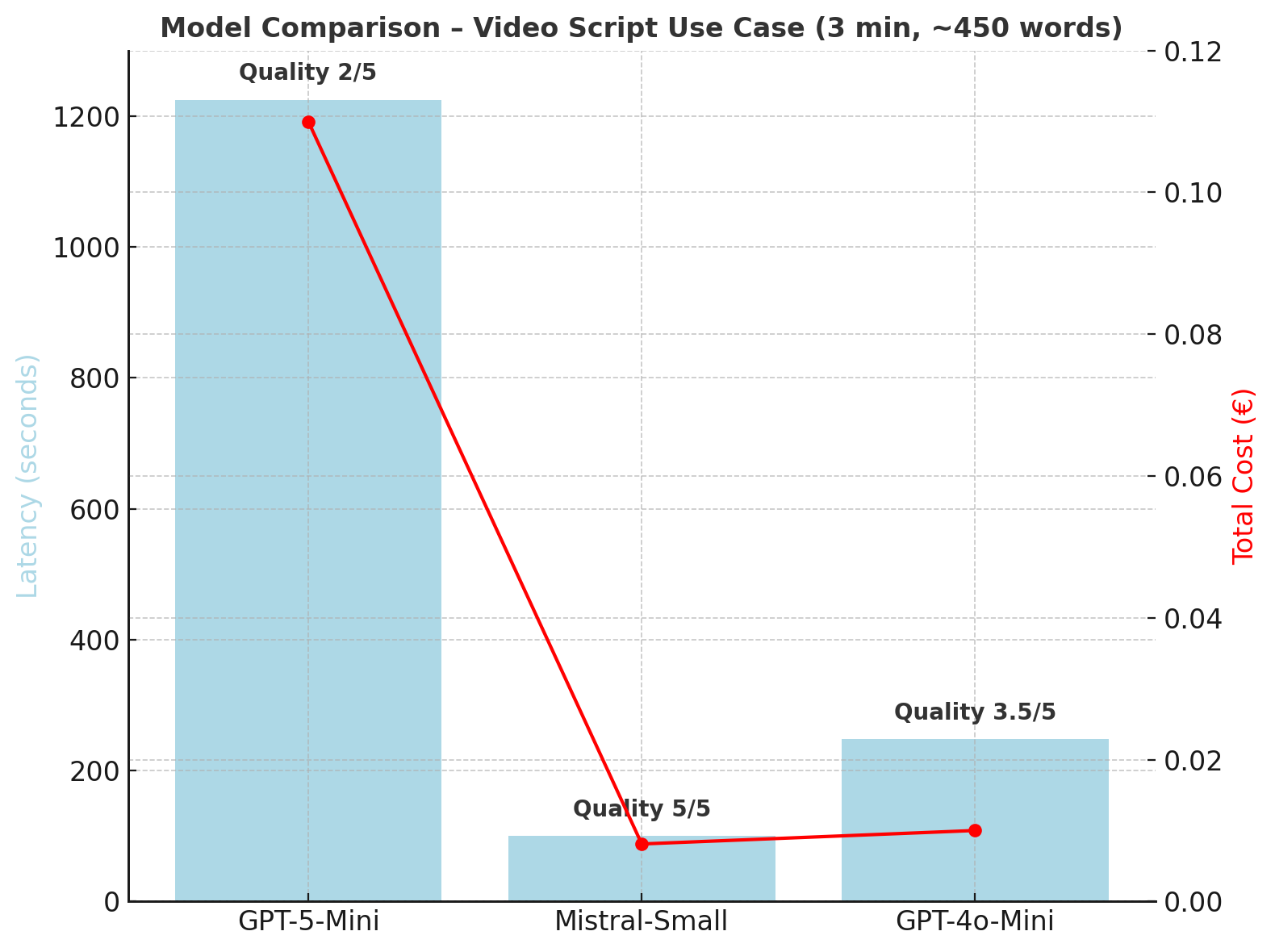
| Model | Total Tokens | Total Latency | Time to First Token | Total Cost | Cost /1k tokens |
|---|---|---|---|---|---|
| GPT-5-Mini | 312,980 | 1,224.7 s (~20 min) | 76.7 s | €0.11 | €0.000351 |
| Mistral-Small | 83,236 | 99.6 s (~1.5 min) | 8.5 s | €0.0081 | €0.000097 |
| GPT-4o-mini | 84,551 | 248.1 s (~4 min) | 97.4 s | €0.01 | €0.000118 |
GPT-5 took over 20 minutes to produce what Mistral delivered in under 2. That’s not just slower — it’s an order of magnitude slower.
Observations
- Mistral-Small: best overall performance. Fastest latency, lowest cost, near-instant first token.
- GPT-4o-mini: inexpensive, but very slow to first token (~97s).
- GPT-5-Mini: extremely high latency (20 min for a 3-min script), significantly higher cost, and an order of magnitude more tokens produced.
Synthetic Ranking
- For short, pedagogical videos (general technical audience):
- Mistral-Small – balanced, factual, fast, cheap.
- GPT-4o-mini – a credible fallback, but stylistically weak.
- GPT-5-Mini – too advanced, verbose, and costly for the task.
- For advanced technical documentation:
- GPT-5-Mini delivers the richest and most detailed content — but at prohibitive cost and latency.
Takeaway
- Mistral-Small is the clear winner for this use case: best trade-off across quality, relevance, and performance.
- GPT-4o-mini is a viable backup, with stylistic tuning.
- GPT-5-Mini shines only for deep technical writing — far beyond the needs of a 3-minute explainer video.
6. Lessons for Applied Engineers
- GPT-5 is not plug-and-play
- No retro-compatibility with existing prompts.
- Much stricter, less tolerant of ambiguity.
- Requires adoption of new APIs (Responses API, verbosity, reasoning_effort).
- Specialized multi-model workflows remain king
- Mistral-Small excels in speed and cost efficiency.
- GPT-4o is a solid all-rounder.
- GPT-5 does not yet replace optimized agentic pipelines.
- Evaluation is non-negotiable
- Benchmarks don’t tell the full story.
- Real-world use cases reveal what models can — and can’t — do.
- Prompt versioning per model is essential.
- Engineering skill matters as much as the model
- Today’s models (GPT-4o, Mistral, Claude, DeepSeek, Qwen…) are already extremely capable.
- The real differentiator is the AI Engineer’s craft: workflow design, pattern mastery, and tool orchestration.
- That’s where applied value is created — not just in picking the “best model.”
The model matters. But the engineering craft — workflow design, prompt strategy, orchestration — is where real value is created.
7. Conclusion – Not Everest Yet, but a Key Step
GPT-5 showed some promise (style, rigor, coherence), but revealed:
- A non-trivial integration cost — the only model failing part of the test suite. OpenAI was right to warn developers: adopting GPT-5 means real changes, and it’s essential to factor that in. To their credit, the accompanying resources (cookbook, prompt optimizer, migration tools) are valuable support.
- A limited functional advantage in complex real-world workflows (video_script) without specific optimization.
For Applied Engineers: GPT-5 is not yet a revolution. Specialized workflows and smaller models remain competitive and often superior.
For decision-makers: choosing between GPT-5, Mistral, Claude, or DeepSeek depends on the use case — but the critical value comes from the engineer’s expertise in workflow design, not just the model.
And the real challenge still lies ahead: agentic-research, the Everest of agentic workflows.
Video_script was a demanding climb — a serious base camp. But Everest is still to come: deep agentic workflows, optimized for GPT-5. That’s where we’ll see if this model can truly deliver on its promise.
In the next article, I’ll explore how to rethink prompts and workflows to be “Designed for GPT-5” — and maybe, finally, reach the summit.
To be continued…